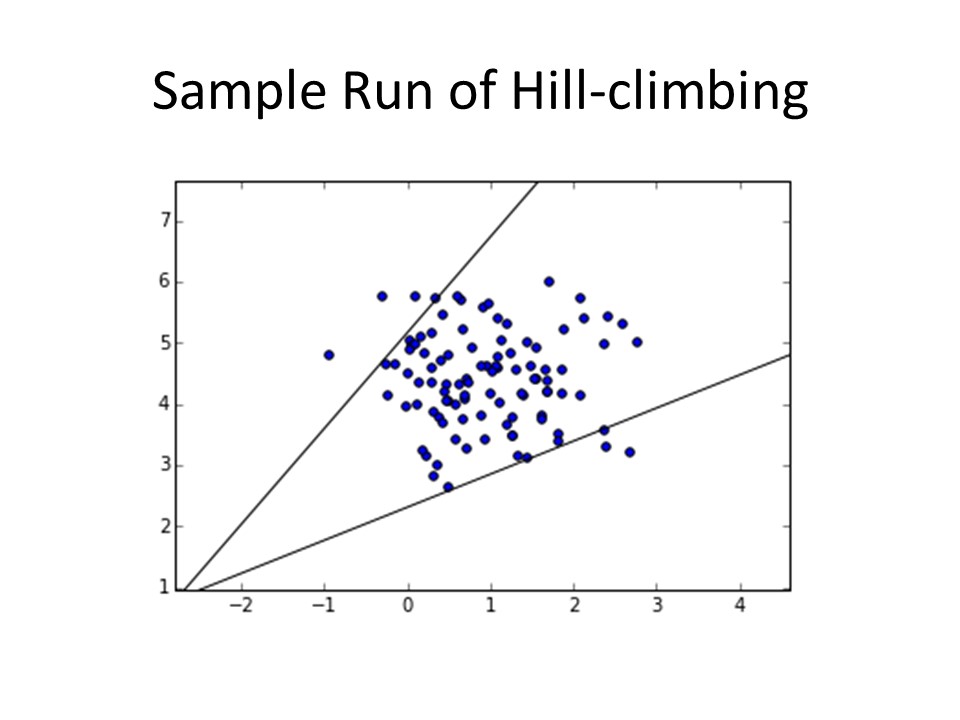
With another round of iterations, a second syntax tree leaf is generated. Which is a fancy way of saying we have two boundary lines for our dataset which optimize the fitness function we created. The procedure of finding more and more tree leaves can be repeated, until a "proper" boundary for the dataset is found. Of course, the number of leaves, and the tightness of the boundary fit is a fitness function itself.
Return to my homepage